大模型评测是大模型研发体系中的关键一环,模型评测能够发现模型缺陷,指导模型优化方向,减少计算资源浪费,持续提升模型性能,确保大模型产品满足用户需求,推动大模型技术迭代进步。然而,现有大模型评测技术仍面临若干严峻挑战:面向大模型能力的客观评价和主观评价难以有机协同;大模型生成能力超过大多现有评测基准;因专业知识与评测专家缺乏,行业垂类大模型评测体系构建难度大;大模型评测数据集来源受限,数据管理、隐私保护存在缺陷……
大模型评测技术论坛拟围绕建立客观、公正、自动化的大模型评测体系展开,邀请各领域顶级专家学者从自然语言处理、软件测试、数据挖掘、数据管理等多个角度重点研讨大模型评测技术关键问题,为各领域专家协同创新、合作共享提供交流平台,助力构建更完善的大模型评测技术体系,推动大模型技术支撑千行百业持续健康发展。欢迎软件测试、软件工程、人工智能、数据科学、数据库等学科的专家和学者前来参加。
01
论坛组织委员会
靳若春(国防科技大学计算机学院)
张奇(复旦大学计算科学技术学院)
谢晓园(武汉大学计算机学院)
02
论坛议程
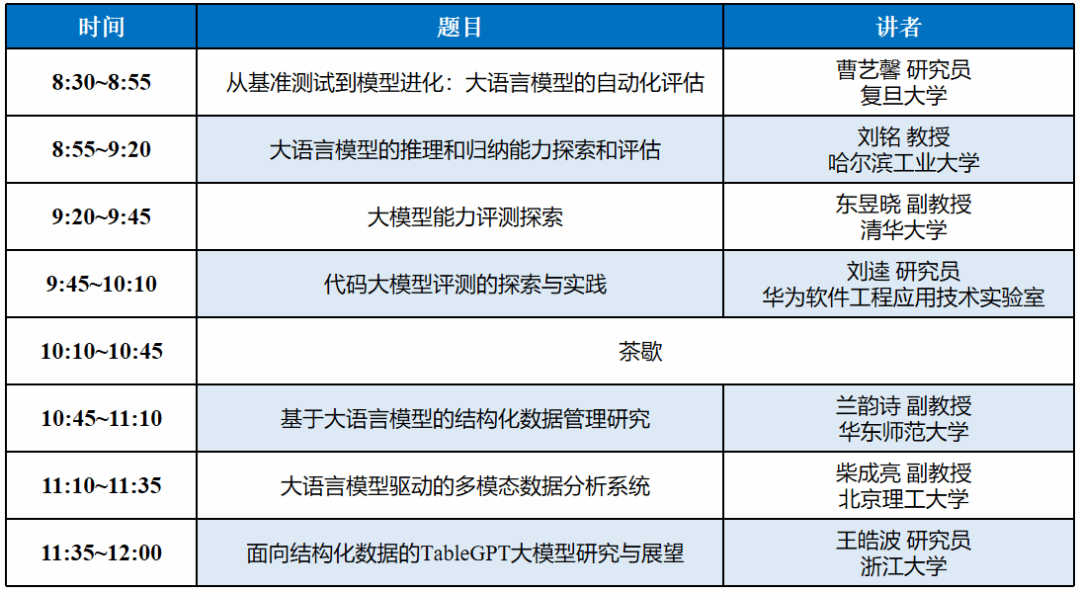
03
论坛报告嘉宾简介

曹艺馨
报告题目:从基准测试到模型进化:大语言模型的自动化评估
报告摘要:
近年来,人工智能(ai)领域目睹了大规模语言模型(llms)所取得的非凡成就。这些模型凭借其巨大的训练语料库,在多种任务上展现出了卓越的能力。尽管如此,模型评估方法的发展却相对滞后。一方面,尽管不断有新的评估数据集被创建,但由于llms遵循扩展法则(scaling laws),它们往往能够迅速超越现有的基准,这使得新数据集的构建成为一项耗时且繁重的任务。另一方面,数据泄露的风险也在威胁当前的评估方法,因为模型在预训练阶段可能已经接触到了部分测试数据。为应对这些挑战,本次演讲将介绍并深入探讨一种创新性凯发k8登录的解决方案:建立一个专为llms设计的自动化评估框架。该框架包含数据集自动生成及基于多智能体系统的自动化测量机制。此外,还将分析此自动化评估框架的稳健性和可靠性。最终,我们将展示如何依据自动化评估的结果来促进模型训练的持续优化(即模型进化)。不仅如此,我们还将超越单纯依赖评估分数的做法,致力于揭示大模型内部的工作机理,从而进一步推动这一领域的透明度和理解深度。
报告人简介:
曹艺馨,复旦大学青年研究员、博士生导师。于清华大学获得博士学位,曾先后在新加坡国立大学、南洋理工大学和新加坡管理大学担任博士后、研究助理教授和助理教授职位。国家级青年人才计划入选者、上海市青年领军人才计划入选者。研究领域为自然语言处理、知识工程和多模态信息处理,在国际知名会议和期刊发表论文60余篇,谷歌学术引用6000余次,并多次被领域内国际顶级会议评为口头报告。研究成果获得两项国际会议的最佳论文及提名,曾获lee kong chian fellowship、google south asia & southeast asia awards和ai2000最具影响力学者奖的荣誉提名。担任多个国际会议演示程序主席、领域主席和国际期刊审稿人。

刘铭
报告题目:大语言模型的推理和归纳能力探索和评估
报告摘要:
随着人工智能技术的飞速发展,大语言模型已成为我们解决多样化复杂问题的关键工具。大语言模型技术的崛起,已经彻底改变了我们对于数据处理和分析的认知方式。凭借其庞大的参数体系和强大的学习及适应能力,大语言模型在自然语言处理、机器学习和数据分析等多个重要领域展现出了无与伦比的强大功能。大语言模型的兴起对许多传统的评测任务带来了明显的冲击,由于传统任务通常在复杂度和多样性方面存在限制,已不足以全面评估大语言模型的性能。基于此,本报告展示了大型语言模型在推理和归纳任务中的表现,并对其进行了全面的评估。为确保评估的全面性与准确性,本报告构建了包含时间推理和趋势预测两个维度的评估数据集。同时,考虑到现实世界的多样性和复杂性,进一步将推理任务扩展到多模态场景,以测试和验证具有代表性的多模态大语言模型在归纳和总结方面的能力。期望通过本次报告,为大家提供一个关于大语言模型在推理和归纳能力方面的充分展示,同时也期望能够促进更多关于大语言模型在各种任务上的评估的讨论和交流。
报告人简介:
刘铭,教授/博士生生导师,哈尔滨工业大学计算学部。先后主持国家重点研发计划项目(课题)、国家自然科学基金、中国博士后科学基金特别资助、中国博士后科学基金面上资助一等资助等基金项目。获黑龙江省科学技术一等奖,哈尔滨市科技成果,第六届全国青年人工智能创新创业大会一等奖。近年来以第一作者或通讯作者发表ccfa/b类论文多篇,英文译著一部。担任多个国内外知名会议的领域主席和程序委员会主席。

东昱晓
报告题目:大模型能力评测探索
报告摘要:
基础大模型在意图感知、指令跟随、目标规划等方面展现出强大的泛化能力,正成为当下人工智能发展的核心技术之一。报告将分享glm系列语言和多模态模型研发过程中对大模型能力评测的探索,包括对齐agentbench、长文本longbench、智能体agentbench、多模态智能体vab、代码ncb和humaneval-x、图片生成imagereward、视频理解lvbench等。同时,我们发现预训练损失可以比模型大小或计算量更好地预测语言模型的涌现能力,进而合理指导模型训练与能力提升。以glm-4 all tools模型为列,其可实现自主理解用户意图,自动规划复杂指令,自由调用网页浏览器、代码解释器以及多模态模型等,以完成复杂任务。
报告人简介:
东昱晓,清华大学计算机系副教授,曾工作于脸书人工智能和微软总部研究院。研究方向为数据挖掘、图机器学习和基础大模型,相关成果获ecml’23, www’22/19, wsdm’15最佳论文奖或提名,应用于十亿级用户社交网络和知识图谱。获sigkdd博士论文奖提名、ijcai early career spotlight、蚂蚁intech科技奖、acm sigkdd新星奖。

刘逵
报告题目:代码大模型评测的探索与实践
报告摘要:
随着大模型技术的飞速发展,代码大模型已经成为软件工程与人工智能交叉领域的重要研究方向。这些模型利用大规模数据集进行训练,能够理解和生成复杂的编程语言结构,对于提高软件开发效率、自动化测试以及代码审查等方面展现出了巨大的潜力。本报告旨在探讨如何对这些代码大模型进行全面且有效的评测,并分享在此过程中的实践经验。通过本报告,我们希望为相关领域的研究人员提供有价值的参考信息,促进代码大模型评测理论与实践的进步,推动ai辅助软件开发技术的进一步成熟与应用。
报告人简介:
刘逵,华为2012实验室智能化软件工程技术专家。2019年毕业于卢森堡大学,获得软件工程专业博士学位,2020年入职南京航空航天大学,2021年12月入职华为,主要从事软件编码、软件测试、程序分析、代码检视等智能化软件工程技术研究工作,在软件工程领域发表高水平研究论文40余篇,其中ccf a类期刊/会议论文20余篇,曾任南京航空航天大学计算机科学与技术学院副教授,主持过国家自然科学基金面上项目一项,江苏省自然科学基金青年项目一项,参与国家重点研发计划项目两项,担任ieee tse、acm tosem、emse、《软件学报》、icsme、saner等国际期刊/会议审稿人。

兰韵诗
报告题目:基于大语言模型的结构化数据管理研究
报告摘要:
大语言模型在人工智能中扮演着重要的角色。在数据库领域,越来越多的研究人员开始聚焦于如何将大语言模型运用于下游任务,如:配置旋钮、测试样例生成和查询生成。其中查询生成(nl2dql)作为结构化数据管理的重要任务,旨在将自然语言自动转化为数据库查询语言。其有着广泛的服务场景和应用前景。基于此,本次报告将首先介绍大语言模型用于查询生成的基本范式,进而介绍我们进行的一些探索,包括设计实现了大语言模型将自然语言转为领域内数据库查询的新框架和方法,最后分享我们在国产数据库上的应用实践。
报告人简介:
兰韵诗,华东师范大学副教授, ccf中文信息学会专委委员,国际acl sigedu专委委员,入选上海浦江人才计划。主要研究方向为自然语言处理,智能问答,大语言模型等。她的研究致力于利用语言模型解决各类场景的问答任务,提升问答效率和精度,从而减少运营成本。兰韵诗博士在机器学习和自然语言处理顶级会议上发表论文四十余篇,担任acl、emnlp、neurips等国际会议程序委员。目前主持国家自然科学基金青年科学基金、国家区域重点项目子课题等。获得国泰君安、阿里云等资助,带领团队深度参与产学研项目,多项成果已在工业界部署上线。

柴成亮
报告题目:大语言模型驱动的多模态数据分析系统
报告摘要:
在当今信息爆炸的时代,数据的多样性和复杂性不断增加,传统的数据分析方法已难以满足数据分析师日益增长的需求。本报告探讨了利用大语言模型(large language models, llms)来驱动多模态数据分析系统的新方法,大语言模型以其强大的自然语言处理能力,为理解和整合这些数据提供了新的视角。本研究首先概述了多模态数据的特点及其在现代数据分析中的重要性。随后,详细介绍了多模态数据表征与存储、系统的查询语言,查询优化方法,包括其在处理表格、文本、图像等数据时的策略和优势。
报告人简介:
柴成亮,北京理工大学计算机系副教授。博士毕业于清华大学,发表数据挖掘、数据库领域国际顶级会议(ccf-a)40余篇,获得国际顶级会议 sigmod 2023 best papers ,中国计算机协会优博,acm中国优博,入选福布斯中国30位30岁以下精英榜单,主持博新计划,国自然面上,国自然青年等项目。

王皓波
报告题目:面向结构化数据的tablegpt大模型研究与展望
报告摘要:
大模型技术的高速发展革新了人机交互和信息获取方式,但是它们在面对精准定量问题中展现出来的”刚性”(输出的准确性和可信性)仍然差强人意。特别的,对于广泛存在于各领域数据库和报表的结构化表格数据,大模型的处理和分析能力仍显不足。在本次报告中,我们介绍团队研发的结构化数据分析大模型tablegpt,其能够在自然语言的交互驱动下,实现对表格或数据库文件的精准增删改查和挖掘分析,并支持可视化图表生成和简单的报告撰写。
报告人简介:
王皓波,浙江大学软件学院百人计划研究员,研究方向包括开放世界下的高效标注技术、面向结构化数据分析的大模型技术等。近年来,在iclr、neurips、ijcai、acl、cvpr、tpami等ccf a类/清华a类顶级国际会议期刊上发表40余篇学术论文,其中一作/通讯18篇。长期担任iclr、neurips、tkde、tpami等顶会和顶刊审稿人,曾担任ijcai 2021 spc,2022年icml杰出审稿人。曾获评iclr 2022杰出论文奖荣誉提名(一作)、吴文俊-中国人工智能学会优秀博士论文奖、waic青年优秀论文提名奖等荣誉。
04
论坛组织委员会简介

论坛主席:靳若春
个人简介:
靳若春,国防科技大学计算机学院助理研究员,爱丁堡大学信息学博士(数据库方向),研究方向为数据库理论与系统、数据质量、大模型评测技术。近年来在sigmod、vldb、icde、tods等ccf-a类数据库顶级会议与期刊发表学术论文10篇,授权/申请专利6项,主持国自科青年基金项目、国家重点实验室课题。担任ccf数据库专委会执行委员、ccf软件工程专委会委员。主讲本科专业必修课《数据科学与大数据基础》。

论坛主席:张奇
个人简介:
张奇,复旦大学计算科学技术学院教授、博士生导师。主要研究方向是自然语言处理和信息检索,聚焦自然语言表示、信息抽取、鲁棒性和解释性分析等。兼任中国中文信息学会理事、中国中文信息学会理信息检索专委会常务委员、中国人工智能青年工作委员会常务委员、sigir beijing chapter组织委员会委员等。在acl、emnlp、coling、全国信息检索大会等重要国际国内会议多次担任程序委员会主席、领域主席、讲习班主席等。近年来承担了国家重点研发计划课题、国家自然科学基金、上海市科委等多个项目,在国际重要学术刊物和会议发表论文150余篇,获得美国授权专利4项,著有《自然语言处理导论》和《大规模语言模型:理论与实践》,作为第二译者翻译专著《现代信息检索》。获得wsdm 2014最佳论文提名奖、coling 2018领域主席推荐奖、nlpcc 2019杰出论文奖、coling 2022杰出论文奖。获得上海市“晨光计划”人才计划、复旦大学“卓越2025”人才培育计划等支持,获得钱伟长中文信息处理科学技术一等奖、汉王青年创新一等奖、上海市科技进步二等奖、教育部科技进步二等奖、acm 上海新星提名奖、ibm faculty award等奖项。

论坛主席:谢晓园
个人简介:
谢晓园,教授、博导,武汉大学特色化示范性软件学院副院长,外国优秀青年学者研究基金获得者,武汉大学珞珈青年学者。研究方向为蜕变测试、软件缺陷定位、智能软件工程等。主持两项国家自然科学基金面上项目,参与多项自科基金重点项目、重点研发项目等。在软件工程顶级或知名期刊会议上录用论文50余篇。曾获nasac青年软件创新奖、acm sigevo humies银奖、acm sigsoft distinguished paper award、湖北省科技进步一等奖、qsic最佳论文奖。担任fcs青年ae、jss客座编辑、历任ieee/acm蜕变测试研讨会pc chair。
